

The company’s latest DGX-1 supercomputer looks like a regular server rack, but has been designed specifically for AI-related workloads to deliver groundbreaking performance three times faster than the previous Pascal-based DGX lineup. Under the hood are eight Volta-based V100 GPUs, each featuring 21 billion transistors and packing 5,120 CUDA cores for a combined computing equivalence of around 800 desktop CPUs. Unlike its modern CPU counterpart, however, DGX-1 with Tesla V100 consumes nearly 40 times less power, and is priced rather competitively despite being comparable to some people’s life savings.

Eight Volta GPUs, 40,960 cores with the same TDP
All in all, the eight Volta GPUs use the same TDP and form factor as the previous eight GPUs on the Pascal-based DGX-1, but now features 1.5 times the memory performance, double the interconnect performance. As we mentioned earlier, the Tesla V100 also includes new “tensor cores” built specifically for deep learning, providing 12 times the teraflops throughput of the P100. We are looking at 120 teraflops of mixed-precision performance on the Tensor cores, 7.5 teraflops of double-precision floating point (FP64) performance, and 15 teraflops of single-precision (FP32) performance.
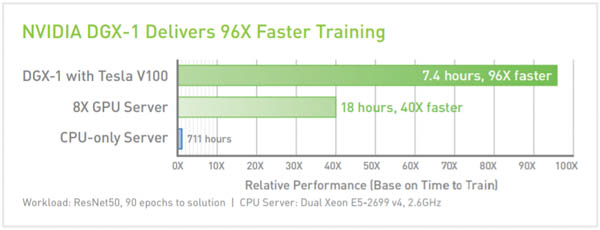
AI training time using a DGX-1 with eight Tesla V100s
In total, the DGX-1 with Tesla V100 features 40,960 CUDA cores and is accompanied by two 20-core Intel Xeon E5 2698 v4 processors running at 2.2GHz each. The commercial system includes four 1.96TB SSDs and runs on Ubuntu Linux.
Six next-generation NVLINK connections
Internally, the system also features six next-generation NVLINK 2.0 interconnects, with each lane now delivering 25Gbps of performance instead of 20Gbps for a combined 300GB/s of bi-directional links between all CPUs and GPUs. We wrote about the next-gen upgrade for NVLINK last August after an IBM slide revealed that the second-gen interconnects would begin appearing in servers sometime in 2017.
“We are going through, unquestionably, the most exciting time in the tech” Huang said. “What we thought was science fiction is coming true as we speak.”
During the keynote, he noted that machine learning has really taken off in universities over the past few years. In 2012, deep learning had finally managed to beat human-coded software. In a previous keynote, he mentioned that 2015 became a landmark year for achieving “superhuman” level of perception.
“It is no coincidence that CS 229 is the most popular course at Stanford,” he said. And indeed, the most popular class on campus at Stanford for the past few years has been a graduate-level machine learning course that covers both statistical and biological approaches to AI.
The Volta architecture inside the latest DGX-1 is expected to accelerate many high-performance computing applications and is slated to appear in the next US supercomputer. The Summit Supercomputer at Oak Ridge National Laboratory will contain multiple IBM Power9 processors and Volta accelerators when it is finalized later this year for deployment in 2018.
Other GPU, FPGA companies will now need to produce AI-specialized accelerators
As some reports have noted, Nvidia is undergoing a transition from producing a deep learning engine optimized for a GPU with Pascal, to a specialized engine for AI with Volta. The folks at Tirias Research expect Volta will quickly trickle down to other platforms, such as the Jetson platform for embedded applications such as drones, robots and self-driving vehicles. Another analysis projects that since the company has taken the market lead on deep learning network networks, other companies that produce GPUs and standard accelerators like FPGA and DSPs will also need to adopt more AI-specialized engines for their consumer and enterprise products to remain competitive in the deep learning world.


