

We got most of the information from the Sumit Gupta and his team. Hi is a VP at IBM Cognitive Systems responsible for AI, Machine & Deep learning products and you can check out a few details about AI in his blog.
The new AC922 server has four to six V100 GPUs with 16 or 32GB and comes with a new Power 9 processor, supports PCIe Gen 4 and the second generation NVlink 2.0 interlink unique to IBM’s platform. The system is targeting the memory coherence as the I/O system gets you to use the 2TB of system RAM almost as fast as the access time of the GPU RAM.
IBM’s four GPU system enables an incredible CPU to GPU bandwidth of 150 GB/s/ CPU to DDR4 memory can only achieve 170 GB/s, so NVlink 2.0 is actually very close to that speed. NVlink 2.0 lets two V100 cards talk to the same 150 GB/s. This is the unique ability of the IBM Power 9 platform.
2TB plus Hash tables data sets
This gives great coherent access to system memory. The whole system address 2TB and this should be enough for very large hash tables. Of course, the system comes with PCIe Gen 4 CAPI 2.0 support. The CAPI 2.0 - unique to the Power 9 processor - enables 32GB /s speeds. CAPI 2.0 Coherent Accelerator Processor Interface is designed as a layer on top of the PCIe that enables direct connection of the CPUI and external accelerations like GPU, ASIC, FPGA or fast storage.
The AC922 accelerated server machine also supports an open source variant of CAPI. OpenCAPI is an Open Standard-based High-speed interconnect for accelerators, storage-class memory, and networking.
The key advantage over the X86 competition - read Intel) -is the memory coherency as you can directly attach the GPU to the system memory. IBM’s advantage is that it can interconnect the GPU to system memory much faster than Intel based machines. The four GPU machine is equipped with InfiniBand and Ethernet and comes as an air-cooled solution.
New AC922 has 6GPUs and Power 9
The new AC922 system now supports six V100 GPUs with both 16GB and 32GB. This system is unique, adding the water cooler to keep the machine at the optimal temperature. While the Power 9 CPU still speaks at 170 GB/s with DDR4 the NVlink 2 speeds drops to 100 GB/s if you use all six cards. You can use 32 GB Volta V100 cards and have a total of 192 GB graphics memory, while the total system memory remains at the magical 2TB (2048GB). Even at 100 GB/s the exchange of data is multiple time faster compared to a Xeon V4 based solution. We will come to that a bit later. 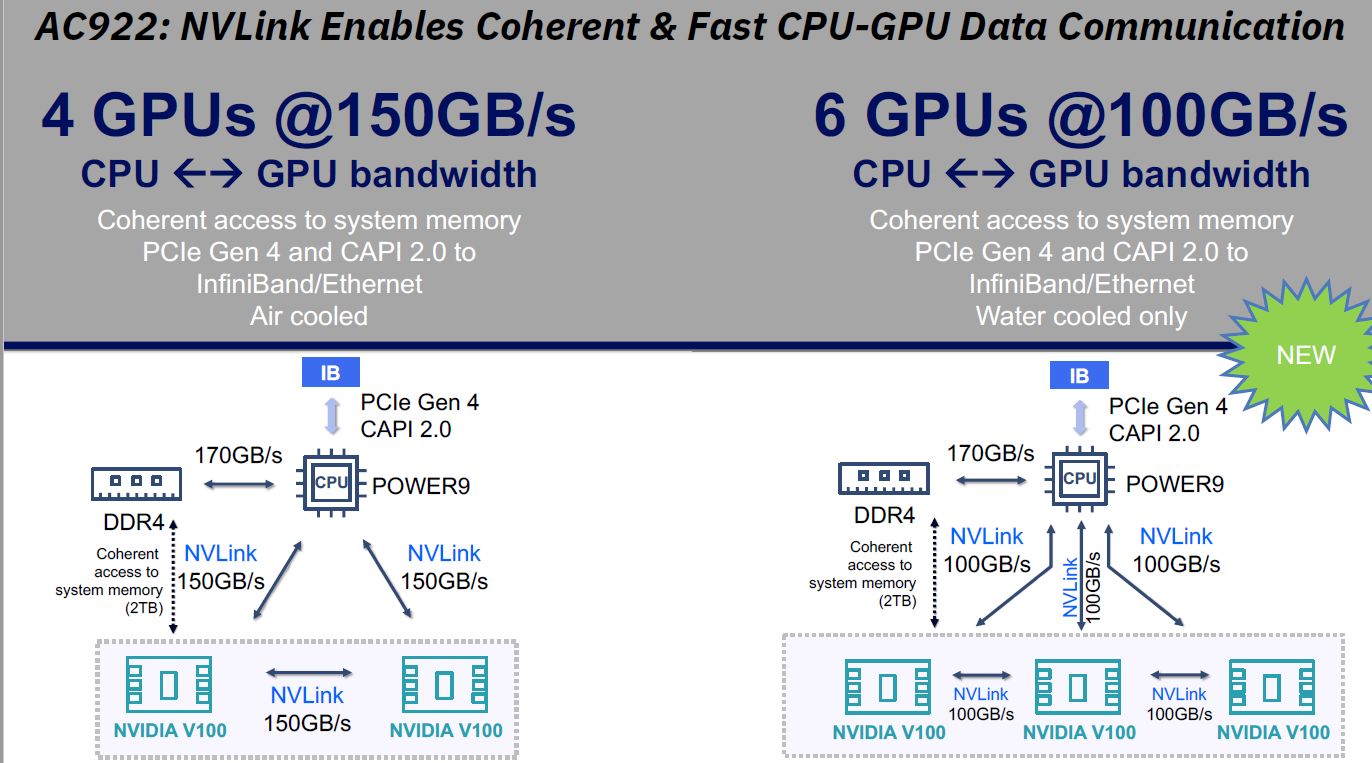
Why do we need all that I/O and memory?
The answer is simple. You need to have large memory size and fast communication between CPU and GPU and system memory for hash tables. Hash tables are fundamental data structures for analytics over large datasets. You can use them in large databases, bloom filters or data lakes. Many might not even have heard about data lakes, but companies which it makes for their customers use these data lakes.
We found a good definition over at kdnuggets.com
“A data lake is a storage repository that holds a vast amount of raw data in its native format, including structured, semi-structured, and unstructured data. The data structure and requirements are not defined until the data is needed.”
The key difference of a data lake compared to a data warehouse, is that the latter has the data structured and processed while the lake has the data sort of structured/semi structured or unstructured at its raw state. Think of it as a desk drawer full of important documents. You know that they are all there, but there is no structure and it can take you hours to make sense out of it.
IBM did some research and claimed that a Power 9 system using four the same GPU can gain 6.2 or even 8.65 speed over an Intel based system. It is hard to argue that Intel Skylake system suffers from the hurdles of the GPU acceleration including small GPU memory limits and the fact that modifications on data in CPU memory does not get updated in GPU memory.
CPU to GPU communication via NVLink2 solves both problems as its 100–150 GB/s high-speed enables storing a full hash table in CPU memory and transferring pieces to GPU for fast operations when needed.
Coherence lets new inserts in CPU memory to get updated in GPU memory.
A CUDA H2D Bandwidth test shows that the P9 system with 2nd generation NV link enables 5.6 X faster data movement from CPU to GPU in a four GPU system. IBM ran some tests and tried to measure the bandwidth and got 12 GB/s with PCIe based Xeon E5 2640 V4 + P100.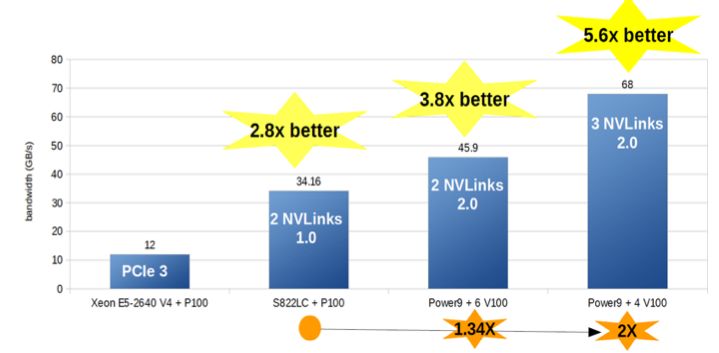
The system based on last year's Power PC bases server S822LC + 9100 scores 34.16 GB using 2 NV link 1.0 (16 /GBs per link), the new Power 9 with 6 V100 using 2 NVlink 2.0 (32 GB/s max bandwidth) scores 45.9 GB/s or 3.8 times faster than an Intel based system.
The king of the benchmark is the new Power 9 system with four V100 GPUs, 3 NVlink 2.0 scoring 68 GB/s or 5.6 times faster than the Intel PCIe 4 based system.
IBM Power AC922 has 32 cores (2 x 16c chips), POWER9 with NVLink 2.0; 2.25 GHz, 1024 GB memory, 4xTesla V100 GPU; Ubuntu 16.04. Last year's Power S822LC for HPC has 20 cores (2 x 10c chips), POWER8 with NVLink; 2.86 GHz, 512 GB memory, Tesla P100 GPU.
Intel’s competitive HW: 2x Xeon E5-2640 v4; 20 cores (2 x 10c chips) / 40 threads; Intel Xeon E5-2640 v4; 2.4 GHz; 1024 GB memory, 4xTesla V100 GPU, Ubuntu 16.04
PCIe 4.0 advantage is quite clear, you get double the speed of PCIe 3.0 and performance can jump from 200 Gbps with PCIe 3 to 400 Gbps with PCIe 4.0
AC922: Unique Capabilities for Enterprise AI
This is the only server that can leverage system memory from GPU side for 2TB+ per node. Intel doesn’t have anything like this right now If you want to run, let’s say, Caffe with LMS (Large Model Support) runtime with 1000 iteration a Xeon X86 based 2640 v4 with 4 V100 GPUs will need 3.1 hours. The same task will be finished in 49 minutes on the Power AC922 with four V100 GPUs.
The important thing to bear in mind is that this is an advantage of the IBM Power 9 architecture as both systems have the same GPU. This is exactly why super-fast Input and output investment was the right bet.
When it comes to distributed deep learning, you can expect the most efficient scaling due to superior I/O between nodes. Using ResNet-50, ImageNet-1K you get 95 percent of ideal scaling 256 GPUS.
IBM also announced new LC922 & LC921 Servers with Power 9 Processors Optimized for Data Stores and even nicknamed them the "big data crushers".