

Dr. Stephen Parker, VP of professional graphics, took the stage to give an overview of the use of artificial intelligence in graphics applications. While the first working algorithm using deep feedforward perceptrons was published around 52 years ago in 1965 by Alexey Ivakhnenko and Valentin Lapa, deep learning in graphics applications has reached a combinatorial explosion thanks to some great work that has been recently accomplished by a group of researchers at the University of Toronto. In 2012, professor Geoffrey E Hinton and two students, Alex Krizhevsky and Ilya Sutskever, entered an image recognition content to build computer vision algorithms that learned to identify millions of objects in millions of pictures. Using the most efficient algorithms at the time, the team was able to take the error rate of an average human and cut it in half. They later created a company called DNNresearch, which Google bought the following year.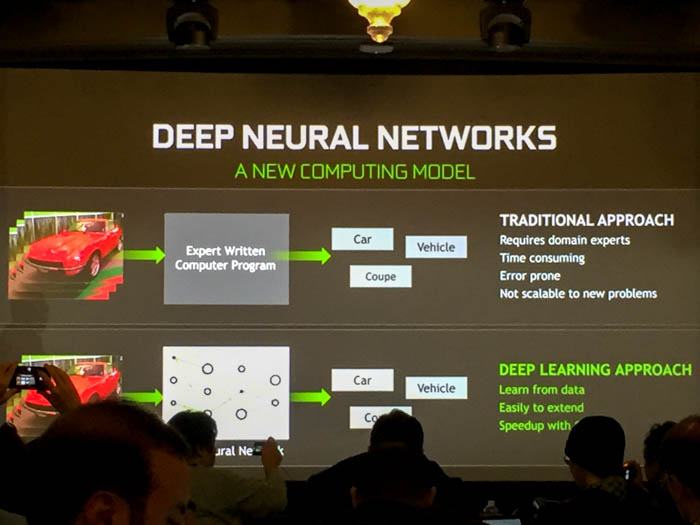
Based on research between 2011 and 2013 from the Google neural network team, Hinton’s team, Stanford, New York University, Université de Montréal, Baudi’s Institute of Deep Learning and several others, advancements in the field have sped up dramatically and by 2015, many large institutions and universities were using deep neural networks to accurately identify objects across billions of given scenes.
“With neural networks, the idea is that results get better with more data, bigger models and more computation,” says Parker. “Of course, having better algorithms, new insights and improved techniques can always help as well. This need for more data has driven an arms race in both data and computation for training these neural networks.”
Deep learning relies on representations of data that are mostly classified as artificial neural networks, or collections of simple, trainable mathematical units that collectively learn complex functions. They work by taking data from an input layer, transforming it at a particular scale in the hidden layer, and then sending it through the output layer to display the eventual output decisions.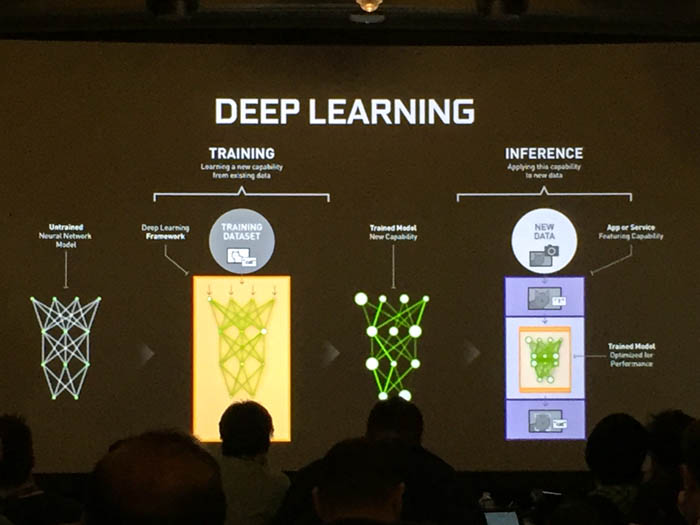
With sufficient training, an ANN can approximate very complex functions by mapping raw data to output decisions. In the world of graphics, the neural network takes a set of pixels and combines them with weights and non-linear operations (the hidden layer) to identify faces, images and other parameters set by a developer.
GPU inferencing instructions are the bread and butter of deep learning efficiency
Parker says that the Pascal architecture has some built-in instructions to really accelerate the performance of training through a process called inferencing. Think of these like the SIMD and MIMD instruction sets used by a modern x86 CPU, only optimized for different types of neural network patterns – convolutional, fully connected, deconvolutional, local response normalization (LRN), etc. The process, however, needs to be fast and efficient in order for the graphics processor to classify, recognize and process generally unknown inputs.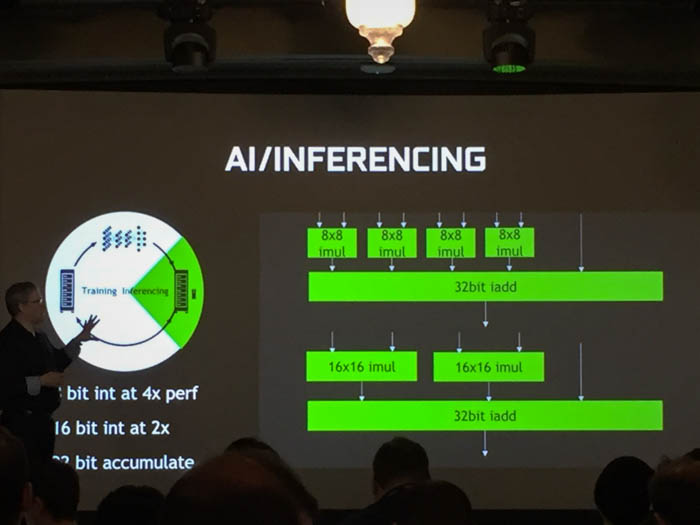
For example, the Tesla P4’s specialized inference instructions based on 8-bit (INT8) operations can deliver up to 45 times faster recognition response times than CPUs, and a four-fold improvement over GPUs from twelve months ago. A single P4 accelerator can replace roughly 13 CPU-only servers for video inferencing workloads, while the deep learning-oriented Tesla P40 can replace the performance of more than 140 CPU servers in a very cost-effective manner.
AI in graphics expected to revolutionize transportation and healthcare
Over the next few years, AI is expected to revolutionize transportation by powering fully autonomous vehicles, revolutionize healthcare by improving the accuracy of diagnoses and image handling, and change the way that we interact with foreign language speakers and with our own computers.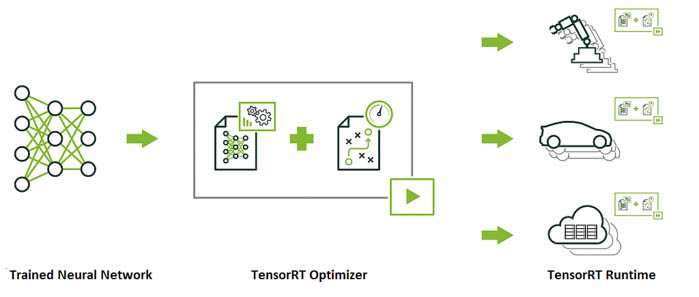
Nvidia has developed a high-performance neural network inference engine called TensorRT that can be used to rapidly optimize, validate and deployed trained neural networks for large datasets in the above mentioned platforms. The company says its INT8 optimized precision can deliver three times more output using 61 percent less memory for applications that rely on highly precise inferencing results.
Style Transfer

One of the important questions of AI in graphics is how it affects content in the future. During the presentation, Parker said that one of the simplest examples of this is called “style transfer”. This is a training method that will feed a neural network a particular picture and tell it to transform the image in a particular style. In late August 2015, researchers from the University of Tübingen published A Neural Algorithm of Artistic Style that demonstrated a way to stylize an art piece in the style of a separate piece. The style transfer algorithm quickly became popular on Facebook and around the world following initial release and was further developed by researchers at the University of Freiburg to be applied to video, albeit with a more challenging technique.
When a deep neural network processes an image, it can encode the image’s style information such as brushstrokes, color and other abstract details and apply this information into the features it infers as the “content” in the second image. In order to make this work for video, the German researchers explain that they had to add several additional constraints to account for object and background consistency from frame to frame.
The resulting algorithm penalizes successive frames from looking too different from one another – which sounds very similar to the work Nvidia, HTC and Oculus have been doing with asynchronous spacewarps to improve framerate consistency for head-mounted displays. The difference, however, is that the style transfer algorithm for video uses image composition techniques between frames to improve object continuity – the image information of a particular area several frames earlier is reapplied to a scene several frames later when the same area reappears.
All in all, researchers using the Pascal-based Titan X have been able to use their style-transfer algorithms to transform high-resolution videos in as little as eight to ten minutes, or about a twenty-fold increase over a modern multi-core CPU. Nvidia says its own researchers have been able to do the same using cuDNN deep learning software, though it admits that real-time artistic style transformation for videos remains “some ways off” for now.


