

I had the privilege to meet Mr. Moore a few years back at one of the IDF shows and his hypothesis has either come to an end or ended in 2018, depending on who you talk to.
Now a new product called the Adaptive Compute Acceleration Platform (ACAP) from Xilinx is here to replace it, it thinks. The key is to make a platform ready for next generation workloads as people today are generating more and more data and the big names like Google, Facebook, Amazon, IBM, Baidu and Alibaba are paying a fortune to make sense of all the data. Intel still claims that Moore’s Law is still alive, but this is hard to justify as Intel itself has been stuck on 14nm for the last four generations, unable to move to a lower node.
I will have to take a step back to 2015 when Nvidia announced yet another 28nm GPU codenamed Maxwell. The Nvidia Geforce leadership with Jeff Fisher and a team of very talented engineers made a crucial decision - to optimize the chip and focus on the gains possible with texture compression. They realized that going to 20nm or 14nm won’t happen anytime soon. The GPU industry was stuck on 28nm for more than four years and the companies had to optimize within 28nm and change the way they dealt with the problems and workloads. Nvidia, back then, was all about pixels and today is targeting workloads and AI systems, as this is the next big thing that is happening as we speak. This has allowed Nvidia to grow to more than $144 billion market cap.
Industry transformation is happening right now with some companies investing in new SoCs such as Xilinx’s Adaptive compute acceleration platform, a SoC designed to deal with next generation workloads. This is a safer and smarter way forward rather than hoping to get to a new manufacturing node every 18 to 24 months.
Going to 10nm was hard, and 7nm is happening for some companies later this year and for most, next year, 2019. Going from 7nm to 5nm, the next generation shrink might take another few years and these chips are getting more and more complex, hard to make and incredibly expensive.
Physics is getting ever harder to beat. Despite being hard to achieve, Xilinx is going down from 16nm TSMC manufactured product to a 7nm with a new SoC codenamed Project Everest. This ACAP (Adaptive Compute Acceleration Platform) is meant to target next generation workloads and projects. Fudzilla has already covered this new innovative technology.
When it comes to AI, it will focus on inference not the training. A GPU is apparently doing quite a good job with training but Xilinx thinks ACAP can help the inference part of the equation. A very important part of the puzzle is that this 7nm chip can adapt to workloads and still deliver dramatically faster performance compared to FPGA.
Nvidia/AMD GPU's approach to AI can only be implemented by software, while Xilinx ACAP can be changed in both hardware and software.
We wrote a separate piece about 7nm ACAP earlier today that has just taped out and can be expected in the hands of customers next year. Fudzilla also learned a lot about the next generation moves and the importance of the Explosion of Data, Dawn of the AI and Computing after Moore's Law from Victor Peng, president and CEO of Xilinx.
Heterogeneous computing with accelerators such as ACAP is the answer, it's claimed, as it can help new apps that address the new workloads. The speed of innovation is outpacing the silicon design cycle, it appears.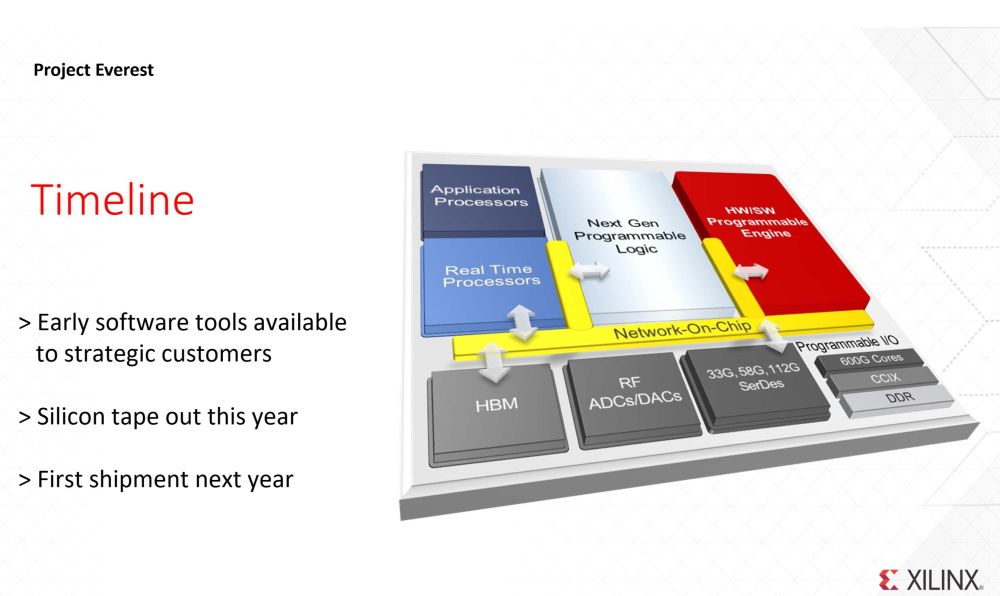
Xilinx has two key parts that differentiate it from the competitors. They have the network on chip component with HBM 2 memory, RF ADC’s / DAC’s and very faster serial DES network. The speeds will go from 33G to 58G, all the way to 112G Serializer/Deserializer. They take care of the extremely fast data transfer on the SoC level. Companies like Nvidia need Intel or IBM platform and its network partners to solve this problem.
The second key thing is the RT processor. RT stands for Real Time processor, a crucial for some mission-critical platforms including the self-driving / Automotive, aerospace and defense, industrial scientific, Medial, test, measure and emulation, audio and video broadcast as well as the wired or wireless communications.
Xilinx believes that adaptive computing accelerating platform can do workloads 10 to 100x faster compared to the CPU, in new workloads and that it can solve and be applied to more used cases than GPU and especially ASICs.
Compared to the last generation ACAP you should see the AI compute capability to increase up to 20 times while the communication bandwidth going forward with 5G will increase by 4 times.
The silicon for the Project Everest will be taped out this year and the first shipment to customers are expected next year. The end result is the software and hardware programmable SoC to address the next generation workloads with 10 times increase in performance as well as performance per watt.


