

After providing a four-hour outage on November 20, Vole 365 is once again experiencing problems. This time it is for the SharePoint Online and OneDrive for Business services where content is not loading or sites are not accessible.
According to advisories issued by Microsoft 365, the outage started at approximately 9:45 AM on the 21st and users were getting messages saying "The server is busy now. Try again later" error when users try to access SharePoint and OneDrive content or sites.
In advisory OO196379 posted to the Microsoft 365 admin centre, Microsoft said that a recent deployment resulted in a code configuration error that caused load balancers to process traffic inefficiently.
Title: Unable to save or load SharePoint Online and OneDrive for Business files User Impact: Users may be unable to load or save SharePoint Online or OneDrive for business files. Current status: Our investigation identified that a recent deployment resulted in a code misconfiguration causing load balancers to process traffic at a suboptimal rate. Our telemetry indicates that the mitigation actions we took have been successful and users should begin to see relief. We're continuing to apply the aforementioned actions and will monitor service health to ensure the fix fully restores service. Scope of impact: This issue could potentially affect any user intermittently when attempting to load or save SharePoint Online or OneDrive for Business files. Start time: Thursday, November 21, 2019, 9:45 AM (2:45 PM UTC) Root cause: A code misconfiguration within a recent deployment caused load balancers to process traffic inefficiently. Next update by: Thursday, November 21, 2019, 6:30 PM (11:30 PM UTC)
While Microsoft states the outage occurred around 9:45 AM, DownDetector shows an earlier start time of approximately 8:30 AM as seen be the timeline of outages reports below.
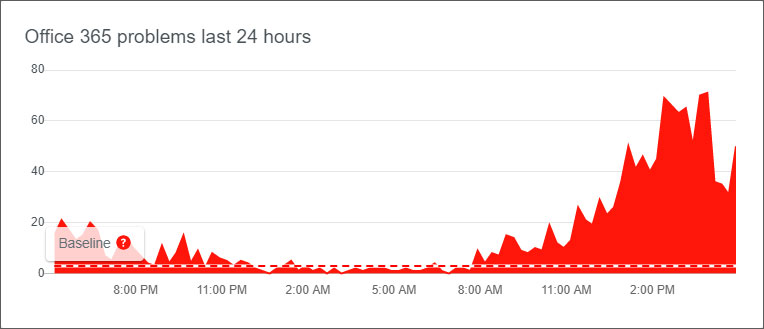
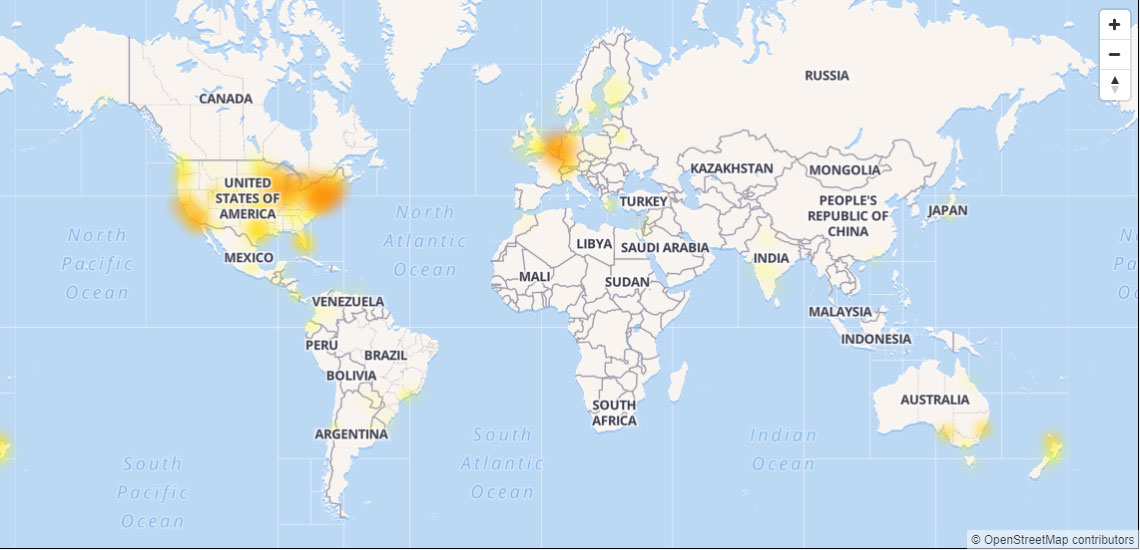
DownDetector also shows that this outage is primarily affecting users in the USA and some portions of Europe.
On the 22 November at 1:15 AM Vole tweeted that it had found the problematic code and resolved the outage.
"We've found a code issue that caused some service traffic to process inefficiently. We rerouted the affected traffic and updated policies on our load balancing infrastructure to fix the problem. See SP196346, OD196347, or OO196379 in the admin portal for final incident details", it said.


