

Xilinx has acquired a company called SolarFlare, a specialist in SmartNIC, and aims to relieve some of the significant compute resources necessary for networking. More than 80 percent of current cloud infrastructure doesn’t have SmartNIC access today. The Xilinx Alveo U25 SmartNIC platform is designed to deliver a true convergence of network, storage, and compute acceleration functions on a single device.
The Alveo U25 SmartNIC is designed to bring greater efficiency and lower Total Cost of Ownership (TCO) benefits of SmartNICs to cloud service providers, telcos, carriers, and private cloud data center operators struggling with increasing networking demands and rising costs.
The U25 combines a highly optimized SmartNIC platform with a powerful and flexible FPGA-based engine that supports full programmability and turnkey accelerated applications. The U25 delivers a comprehensive SmartNIC platform to address the industry’s most challenging demands and workloads such as SDN, virtual switching, NFV, NVMe-oF, electronic trading, AI inference, video transcoding, and data analytics.
SmartNIC reduces latency by 80 percent
Like most Xilinx products, the U25 card is fully programmable via Vitis Unified development environment offering Turnkey applications that cover a broad set of compute problems for smaller cloud providers. SmartNIC is designed to lower the total cost of data center infrastructure, and at the same time, adding an IP to optimize extending certain functionality gives Alveo U25 a lot of leverage versus the traditional platform. Instead of talking to the CPU all the time, SmartNIC can do some tasks directly on the SmartNIC saving a lot of resources in the data center.
The Alveo U25 SmartNIC features two 10/25G ports, two PCIe Gen3x8, SFP28 Direct Attach Copper and SR Optical. It comes in the HHHL form factor. It supports Onload, TCP Direct, NETDEV, and DPDK Pool driver mode for Acceleration and Low Latency.

Baseline NIC features stateless and tunneling offloads, LSO/TSO, RSS, Checksum, SR-IOV, Multiqueue, NetQueue, and 2048 vNICs support. It supports NVMe/TCP for kernel and userspace. The FPGA programmable part includes 520K LUTs, Quad ARM A53 processor complex, and 6GB DDR4 SDRAM.
FPGA Bump-In-The-Wire Acceleration supports OVS, Encryption, Security ACLs, DPI as well as Machine Learning, Video Transcoding and Data Analytics.
Solarflare based technology have already been proven in the field. They are currently deployed in the enterprise, telecom and cloud data centers for some of the world’s most demanding customers including Nasdaq, Shanghai stock exchange and NYSE Euronext.
OnLoad on every Alveo SmartNIC card
The platform enables ‘bump-in-the-wire’ network, storage, and compute offload and acceleration functions for maximum efficiency by avoiding unnecessary data movements and CPU processing. Bump in the wire dramatically reduces the CPU burden, and reclaims resources to run more applications. Embedded ARM processors provide unique and critical control plane processing to support emerging bare metal server use cases. The baseline NIC delivers ultra-high throughput, small packet performance, and low-latency.
Standard full-featured NIC functionality and drivers, including Onload application acceleration software, can reduce latency up to 80 percent and improve transmission control protocol (TCP)-based server application efficiency by up to 400 percent in cloud-based applications.
“Today’s cloud infrastructures suffer from critical data bottlenecks caused by server I/O”, said Donna Yasay, vice president of marketing, Data Center Group at Xilinx. “With up to 30 percent of data center compute resources allocated for networking I/O processing, overhead continues to grow along with CPU cores. Xilinx is addressing the challenges resulting from the increased demands on networking by providing an easier to deploy SmartNIC with turnkey accelerated applications and out-of-the-box capabilities that go far beyond fundamental networking.”
The first out-of-the-box accelerated application available on the Alveo U25 SmartNIC is support for Open vSwitch (OVS) offload and acceleration. The plug-and-play solution will offload over 90 percent of OVS processing from the server to improve packet throughput by over 5X.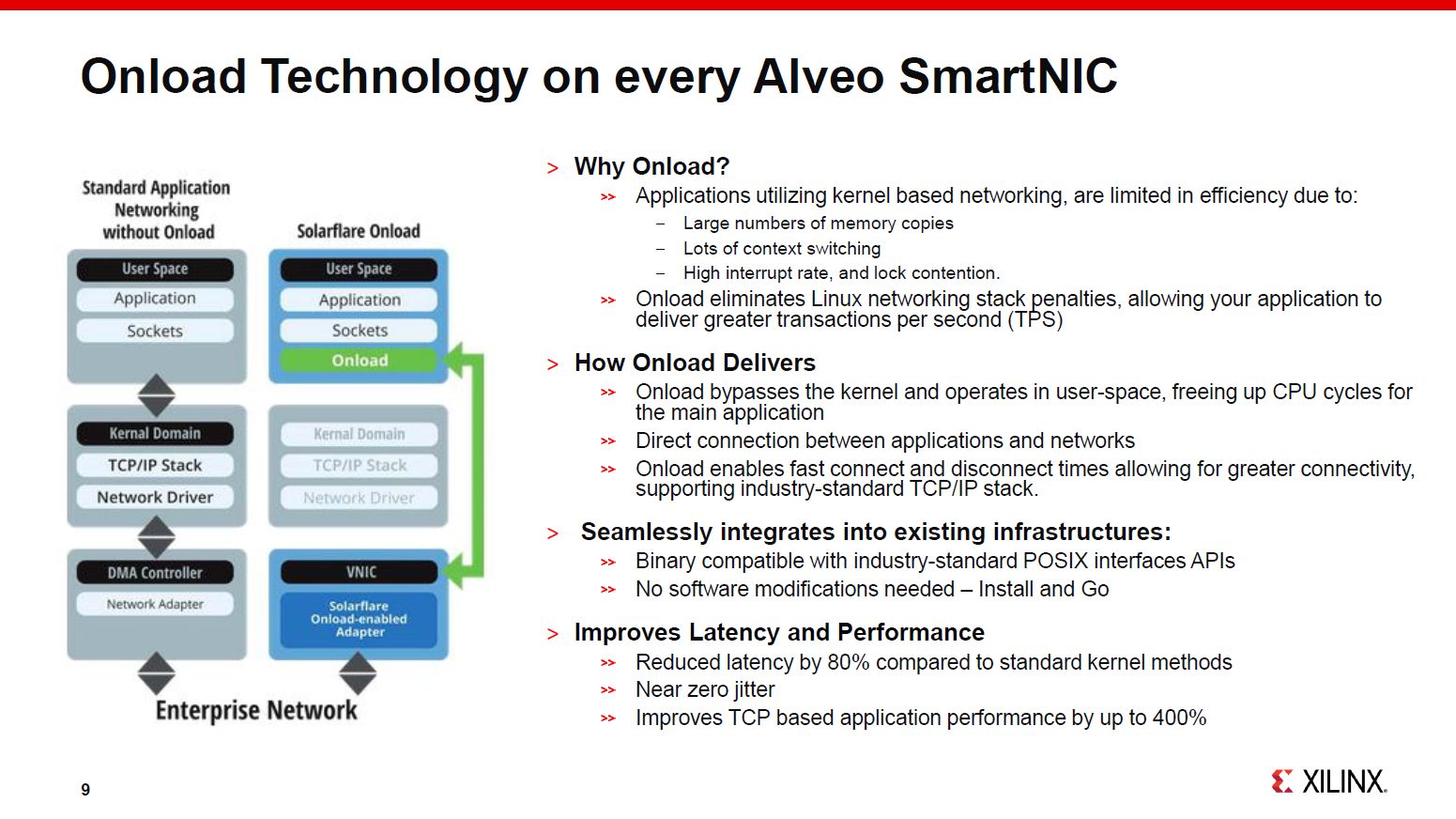
Future turnkey solutions from Xilinx are planned for security functions such as IPSec, SSL/TLS, AES256/128, and distributed firewall as well as AI inference acceleration. The Alveo U25 SmartNIC is currently sampling with early access customers. General availability is expected in the third calendar quarter of 2020.
Turnkye solution for 10s of million clouds
Offload turnkey solution can help Xilinx target 1.4 million servers from the legacy telecoms, small-medium business, and legacy enterprise. With Offload extensible, Xilinx has a shoot with T2 Cloud CSP + ASP customers, including CSP and Telecos, ASP (Application Server Providers), as well as Hybrid and Private cloud. The total market reaching this solution is around 6.8 million servers.
Targeting T1, Hypercloud customers including Amazon, Google, Microsoft and China BAT would require some programmable solutions on top of the Alveo U25 out of the box functionality, but it would increase the potential customer base by an additional 5 million servers.
Xilinx also introduced first OCP 3.0 Ethernet Adapter and OCP Accelerator Module and also unveiled the new XtremeScale X2562 10/25Gb Ethernet adapter card based on the OCP Spec 3.0 form factor.
Designed for high-performance electronic trading environments and enterprise data centers, the X2562 features sub-microsecond latency and high throughput with ultra-scale connectivity for real-time packet and flow information to thousands of virtual NICs.
The X2562 is currently sampling and will be generally available in the second calendar quarter of 2020.
Additionally, Xilinx announced a proof of concept for the world’s first FPGA-based Open Compute Accelerator Module (OAM). Based on the Xilinx® UltraScale+ VU37P FPGA with 8GB of HBM memory and compliant with Open Accelerator Infrastructure (OAI), the mezzanine-based card supports seven 25Gbps x8 links to enable rich inter-module system topologies for distributed acceleration.


