

Index
- Nvidia Geforce RTX-series is born
- Turing architecture and RTX series
- The new Turing architecture in more details
- Shader improvements and GDDR6 memory
- Nvidia RTX Ray Tracing and DLSS
- The Geforce GTX 2080 Ti and GTX 2080 graphics cards
- Test Setup
- First performance details, UL 3DMark
- Shadow of the Tomb Raider, Assassin’s Creed: Origins
- The Witcher 3, Battlefield 1
- F1 2018, Wolfenstein II: The New Colossus
- Power consumption, temperatures and overclocking
- Conclusion
- All Pages
The new Turing architecture in more details
The Turing GPU has a complex design, which brings a new core architecture, Tensor and RT Cores, as well as advanced shading, Nvidia NGX for deep learning, NVLink, USB-C and Virtual Link, and more.
The Turing GPU is based on 12nm FNN manufacturing process, and at 18 billion transistors, it is the second biggest GPU Nvidia made.
The fully-enabled TU102 GPU features a total of six Graphics Processing Clusters (GPCs), 36 Texture Processing Clusters (TPCs), and 72 Streaming Multiprocessors (SMs). Each GPC comes with its dedicated raster engine and six TPCs.
Each TPC comes with two SMs, each with 64 CUDA cores, eight Tensor Cores, a 256KB register file, four texture units and 96KB of L1/shared memory, as well as an RT core. When compared to the Pascal GPU, Nvidia raised the L1 cache bandwidth and lower the L1 latency, by using the shared 96KB memory and also doubled the L2 cache to 6MB per TPC.
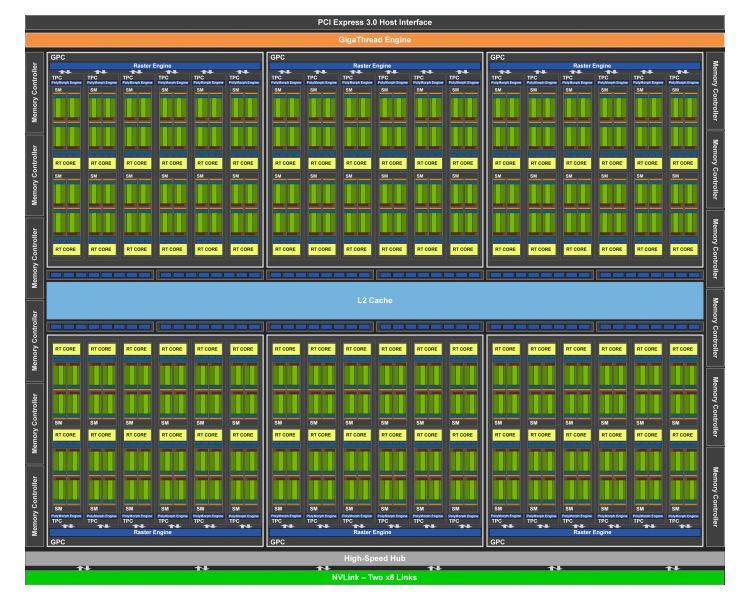
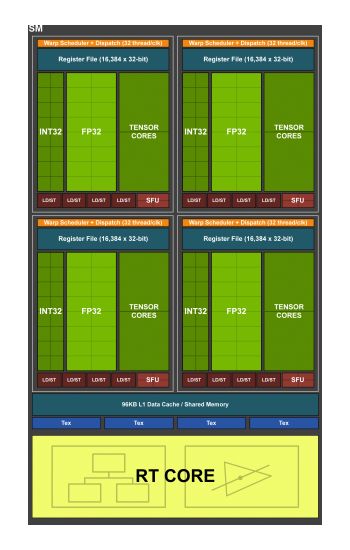
The new Turing Streaming Multiprocessor (SM) pulls some features from the Volta architecture and each SM is split into four blocks, each with 16 FP32 Cores, 16 INT32 Cores, two Tensor Cores, warp scheduler, and dispatch unit, with each block coming with L0 instruction cache and a 64KB register file.
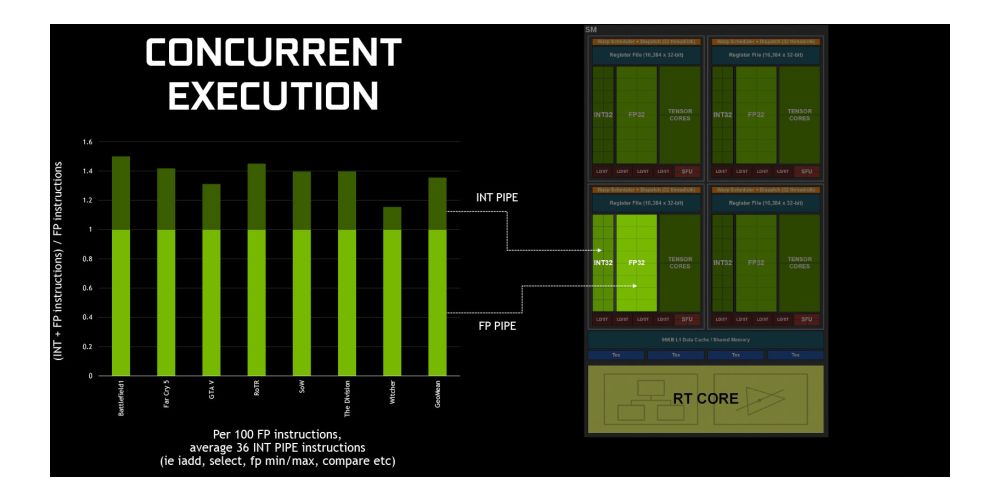
While the Pascal GPU stuck with one SM per TPC and 128 FP32 cores per SM, the Turing SM actually support concurrent execution of FP32 and IN32 instructions. According to Nvidia, modern applications usually have 36 integer pipe (INT) instructions for every 100 floating point (FP) instructions, so by moving them to a separate pipe, translates to an effective 36 percent addition throughput for floating point.
Nvidia has brought the Tensor Cores from its Volta architecture to Turing, and these add INT8 and INT4 precision modes for the so-called inference workloads, as well as full support FP16 workloads for higher precision. More importantly, the Tensor Cores are what allows the Turing GPU to take advantage of Nvidia’s AI-based features in its NGX Neural Services, which include the Deep Learning Super Sampling (DLSS), AI InPainting, AI Super Rez, and AI Slow-Mo.
In terms of numbers, each tensor core is capable of delivering 455 TOPS INT4, 228 TOPS INT8, and 114 TFLOPs of FP16 compute performance.

Each TPC inside the Turing GPU also comes with an RT Core, a dedicated part of the Turing GPU which should bring the holy grail of graphics, Ray Tracing, to the gaming market. Of course, even dedicated RT Cores would not bring a fully Ray Traced scene, which takes a lot of GPU power, but rather what Nvidia calls hybrid rendering, or a combination of Ray Tracing, or to be precise Ray Tracing specific effects, like global illumination, ambient occlusion, shadows, reflections, and refractions; and standard rasterization rendering technique.
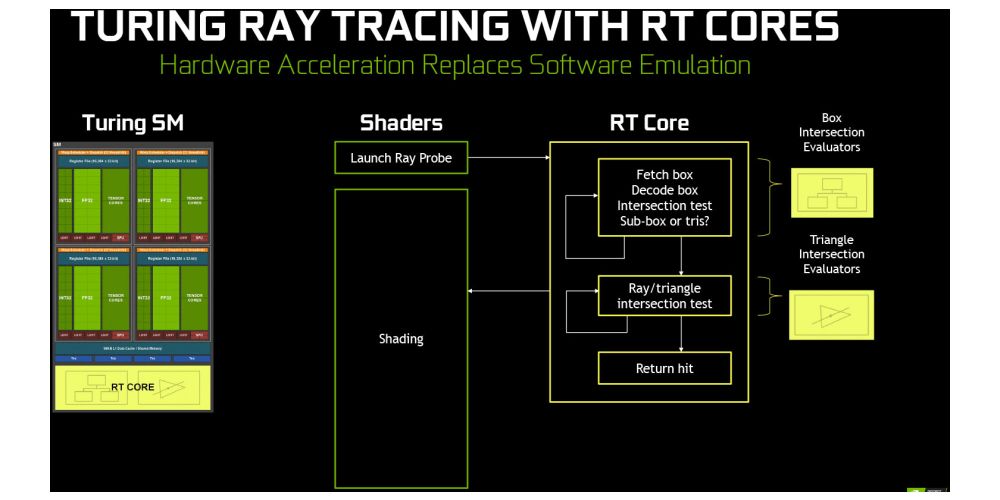
While we are yet to see any actual implementation of Nvidia RTX Ray Tracing, other than a demo, future UL Ray Tracing benchmark, or the demos we saw during Gamescom 2018 with Battlefield V, Shadow of the Tomb Raider, Metro Exodus, and some other games, these, as well as the excitement from developers, suggest that this should bring both incredible eye-candy and level of realism to future games.


